Ensemble models are a great tool to fix the variance-bias trade-off which a typical machine learning model faces, i.e. when you try to lower bias, variance will go higher and vice-versa. This generally results in higher error rates.
Total Error in Model = Bias + Variance + Random Noise
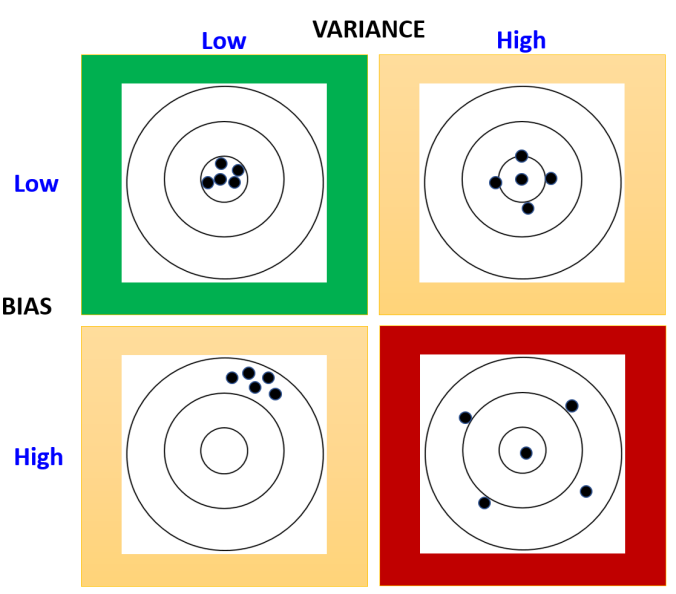
Variance and Bias Trade-off
Ensemble models typically combine several weak learners to build a stronger model, which will reduce variance and bias at the same time. Since ensemble models follow a community learning or divide and conquer approach, output from ensemble models will be wrong only when the majority of underlying learners are wrong.
One of the biggest flip side of ensemble models is that they may become “Black Box” and not very explainable as opposed a simple machine learning model. However, the gains in model performances generally outweigh any loss in transparency. That is the reason why you will see top performing models in many high ranking competitions will be generally an ensemble model.
Ensemble models can be broken down into the following three main categories-
- Bagging
- Boosting
- Stacking
Let’s look at each one of them-
Bagging-
- One good example of such model is Random Forest
- These types of ensemble models work on reducing the variance by removing instability in the underlying complex models
- Each learner is asked to do the classification or regression independently and in parallel and then either a voting or averaging of the output of all the learners is done to create the final output
- Since these ensemble models are predominantly focuses on reducing the variance, the underlying models are fairly complex ( such as Decision Tree or Neural Network) to begin with low bias
- An underlying decision tree will have higher depth and many branches. In other words, the tree will be deep and dense and with lower bias
Boosting-
- Some good examples of these types of models are Gradient Boosting Tree, Adaboost, XGboost among others.
- These ensemble models work with weak learners and try to improve the bias and variance simultaneously by working sequentially.
- These are also called adaptive learners, as learning of one learner is dependent on how other learners are performing. For example, if a certain set of the data has higher mis-classification rate, this sample’s weight in the overall learning will be increased so that the other learners focus more on correctly classifying the tougher samples.
- An underlying decision tree will be shallow and a weak learner with higher bias
There are various approaches for building a bagging model such as- pasting, bagging, random subspaces, random patches etc. You can find all details over here.
Stacking-
- These meta learning models are what the name suggest. They are stacked models. Or in other words, a particular learner’s output will become an input to another model and so on.
Working example-
Let’s build a RandomForest model with Hyperparameters optimization on the Wine dataset from UCI repository. We will follow following main steps-
- Import necessary packages
- Magic command to print many statements on the same line
- Import dataset from UCI website URL
- Explore dataset
- Rename columns to remove spaces from the column names
- Explore dataset again
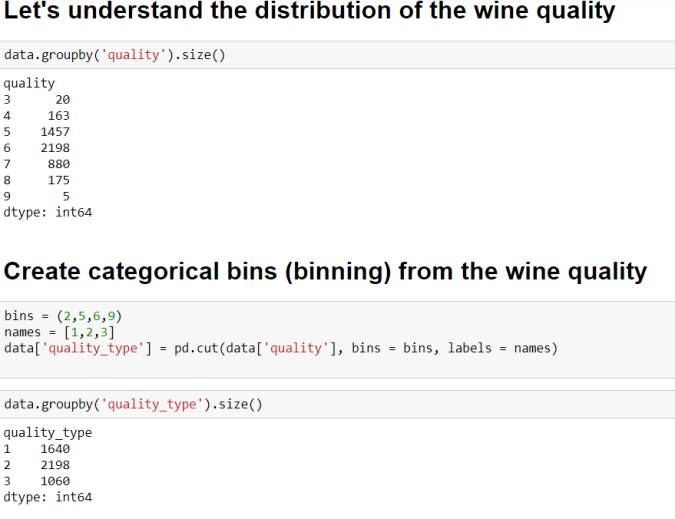
- Understand distribution of the wine quality
- Create categorical bins (binning) from the wine quality
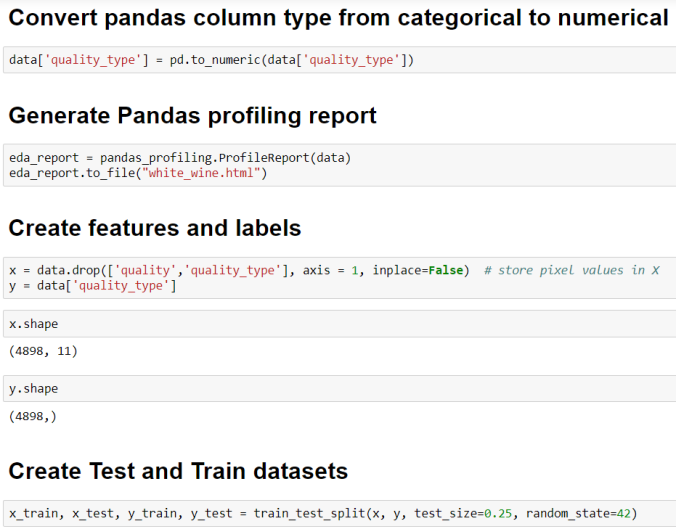
- Convert pandas column type from categorical to numerical
- Generate Pandas profiling report. More on this package can be found here.
- Create features and labels
- Create Test and Train datasets
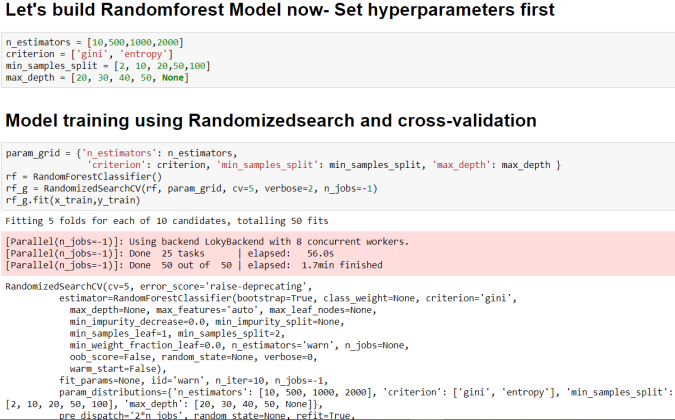
- Build Randomforest Model now- Set hyperparameters first
- Model training using Randomizedsearch and cross-validation
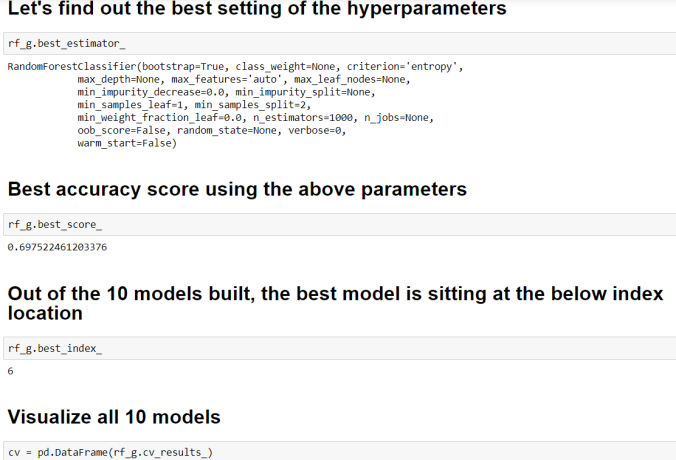
- Find out the best setting of the hyperparameters
- Find out the best accuracy score using the above parameters
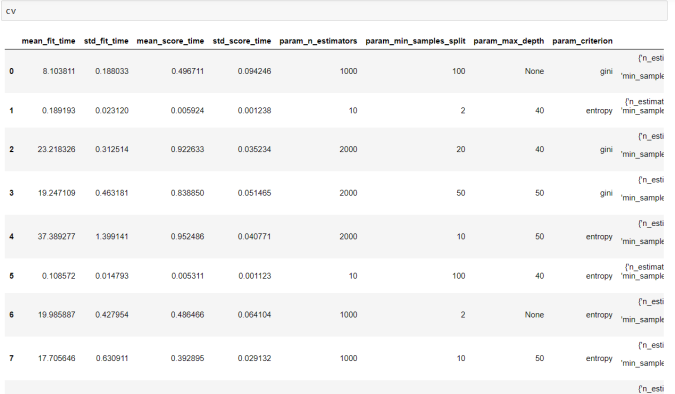
- Visualize all 10 models
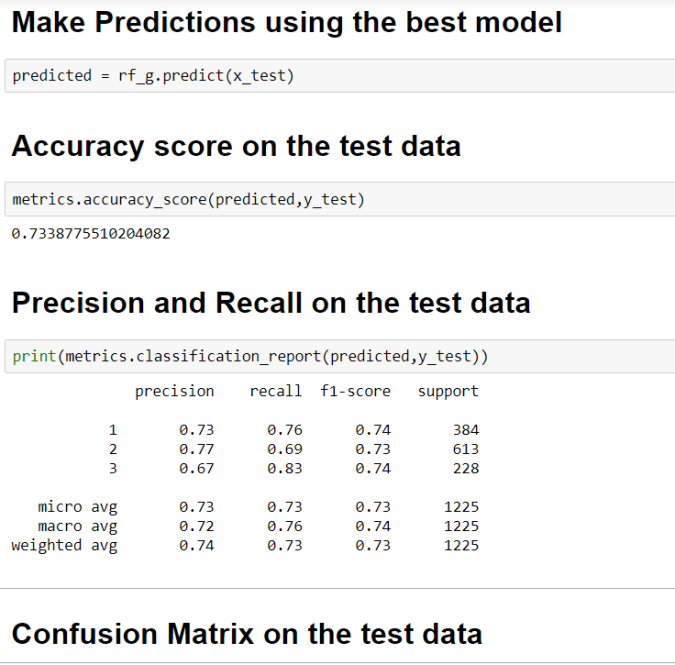
- Best accuracy score on the using the above parameters
- Precision and Recall on the test data
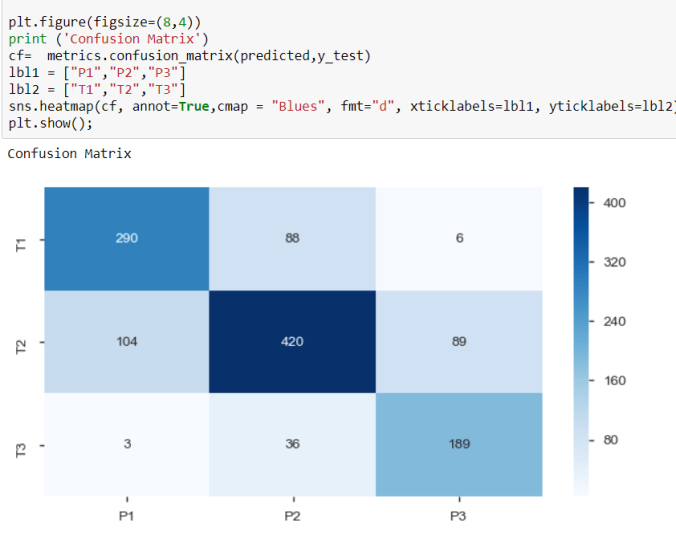
- Confusion Matrix on the test data

Cheers!

You must be logged in to post a comment.